

As a cloud storage user, you may need to copy files from one location to another, either within the same bucket or across different buckets. Thankfully, the AWS S3 copy command lets you copy files without the hassle.
Not a reader? Watch this related video tutorial!In this tutorial, you will learn how to use the AWS S3 copy command through practical examples to copy local files to your AWS S3 bucket.
Ready? Read on and add more ways to manage your AWS S3 storage efficiently!
Prerequisites
This tutorial will be a hands-on demonstration. If you’d like to follow along, be sure you have the following.
- An IAM user with the AmazonS3FullAccess permission.
- A local machine with the AWS CLI installed and configured – This tutorial uses Windows 10 and PowerShell 7.
- An AWS bucket with directories to copy files to and from.
Copying a File with the AWS S3 Copy Command
The essential task an admin can perform with the AWS S3 service is to upload a single file from their computer or server to an S3 bucket. This task can be achieved with a single aws s3 cp command.
The basic syntax for the aws s3 cp command is as follows where:
<local/path/to/file>– is the file path on your local machine to upload.<s3://bucket-name>– is the path to your S3 bucket.
aws s3 cp <local/path/to/file> <s3://bucket-name>
Suppose you plan to copy a single text file to your S3 bucket. If so, the command below will suffice.
Run the command below to upload a text file (text01.txt) from your user home folder (C:\Users\Admin\) to an S3 bucket named test-s3-bucket-0001. The S3:// prefix starts the S3 bucket for the command to work.
Note that you can use your own files to copy to and from your S3 buckets or local machine throughout this tutorial.
aws s3 cp C:\\Users\\Admin\\text01.txt s3://test-s3-bucket-0001/text01.txt
If the upload is successful, you will see a message similar to the one below. This output indicates the file was uploaded to your S3 bucket.

Now, run the below command to list (ls) the files inside your S3 bucket (s3://test-s3-bucket-0001/).
aws s3 ls s3://test-s3-bucket-0001/
Below, you can verify the file (text01.txt) you uploaded to your S3 bucket.

Copying Multiple Files to S3 Buckets
You’ve just uploaded a file to your S3 bucket with just a single command. But most of the time, you’ll have to upload tons of files in one go. Can the aws s3 cp command handle that task? Yes, by appending the –recursive flag.
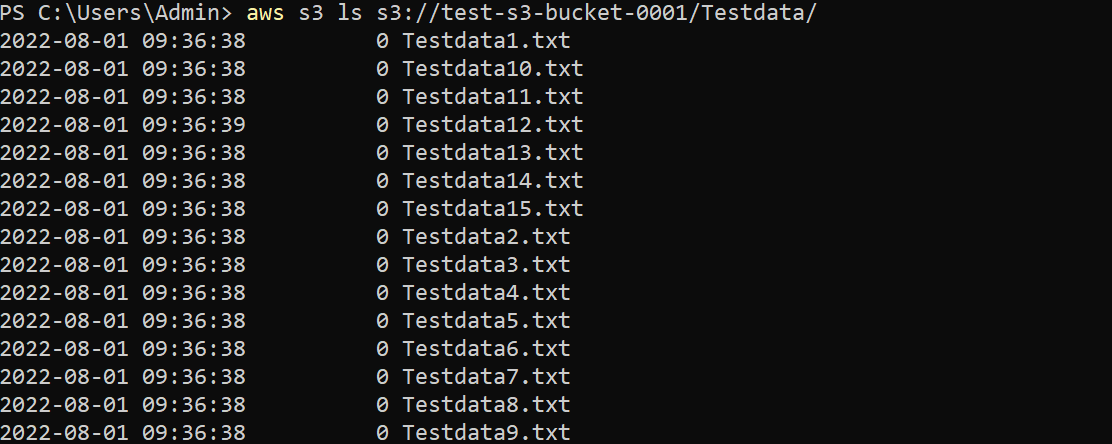
Run the below command to copy an entire directory (C:\Testdata\) to your S3 bucket.
When you append the –recursive flag, any files in the specified directory will be copied to your S3 bucket. The structure of the directory will also be maintained in the bucket, which is helpful when you want to copy the contents of an entire directory without specifying each file individually.
aws s3 cp C:\\Testdata\\ s3://test-s3-bucket-0001/Testdata --recursive
You will see an output like the one below, which shows all files were successfully copied to your S3 bucket.
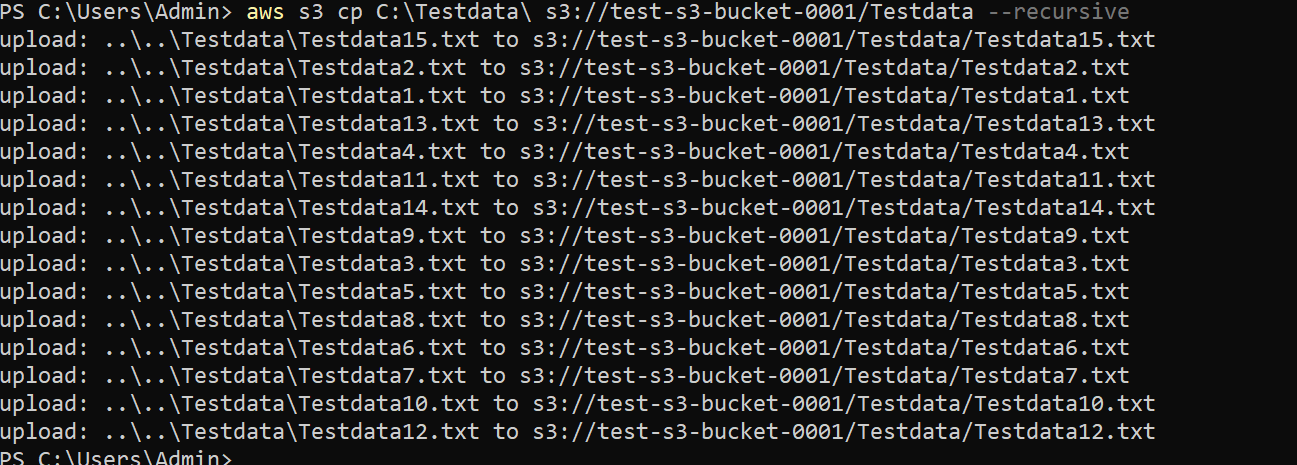
Now, run the following command to list (ls) all files inside the Testdata directory under your S3 bucket (s3://test-s3-bucket-0001/Testdata/).
aws s3 ls s3://test-s3-bucket-0001/Testdata/
You will see all the files you copied from your computer in the output below.
Copying a Local File to S3 with an Expiration Date
One of the tasks you might need to perform when using S3 is copying a file from your computer to an S3 bucket and setting an expiration date for the file. An expiration date is often set to a file for security reasons, making certain files accessible only for a certain period.
For instance, if you have a file named passwords01.txt that you only want to be accessible for 30 days from this day (August 1st).
Run the below command to copy a file (passwords01.txt) to your S3 bucket (s3://test-s3-bucket-0001) with an expiration (–expires 2022-08-30T00:00:00Z).
aws s3 cp C:\\Testdata\\passwords01.txt s3://test-s3-bucket-0001/passwords01.txt --expires 2022-08-30T00:00:00Z
You will see an output similar to the one below, which shows the file was successfully copied to your S3 bucket with an expiration date of 30 days from this day (August 1st).
After 30 days, this file will no longer be cached and accessible from your S3 bucket.

The aws s3 cp command expects an ISO 8601 formatted date string (YYYY-MM-DDTHH:MM:SSZ) to be passed in for the –expiresflag. This format is an international standard for representing dates and times. So if you put an incorrect date format, you will get the below Parameter validation failed error.

Performing a Dry Run of the AWS Copy Command
By now, you already know how to copy files and an entire directory to your S3 bucket. But in some cases, you might want to test the aws s3 cp command without copying any files. Doing so helps prevent messing things up, especially if you’re copying project files.
This situation is often referred to as a “what-if” scenario, which is helpful when you want to see what will happen when you execute the command.
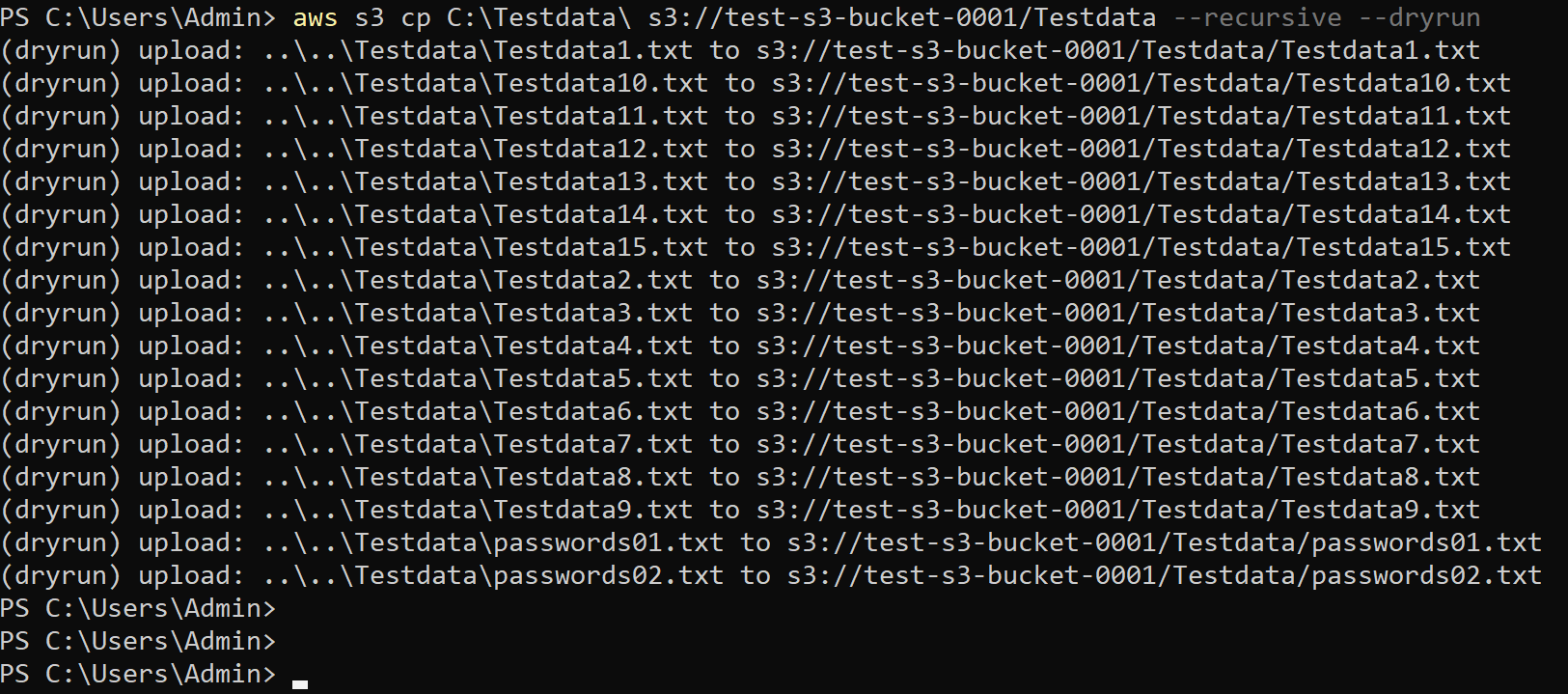
Run the following command to perform a dry run (–dryrun) of copying files from your Testdata directory to your S3 bucket (s3://test-s3-bucket-0001).
aws s3 cp C:\\Testdata\\ s3://test-s3-bucket-0001/Testdata --recursive --dryrun
Below, you can see a list of files that would have been copied to your S3 bucket.
Suppressing All Output Except Errors
Perhaps you only want to see the generated errors when copying files to your S3 bucket instead of seeing an output of files you copied to your S3 bucket. If so, appending the --only-show-errors flag will do the trick.
The –only-show-errors flag comes in handy in debugging your command in case something goes wrong.
Run the below command to copy all files from your local C:\Testdata directory to your S3 bucket (s3://test-s3-bucket-0001) in the directory called Testdata03.
aws s3 cp C:\\Testdata\\ s3://test-s3-bucket-0001/Testdata03 --recursive --only-show-errors
None of the successful file copy outputs that are normally displayed on the output below are shown. Instead, only a blank screen is displayed since this command generated no errors.

Now, rerun the same command with a non-existed local path (C:\non-existed) to replicate an error.
C:\\Users\\Admin> aws s3 cp C:\\non-existed s3://test-s3-bucket-0001/Testdata03 --recursive --only-show-errors
This time, you’ll see an error output similar to the one below since the C:\non-existed directory doesn’t exist.

Conclusion
You’ve seen that the AWS S3 copy command is useful in copying files from one place to another, specifically from a local directory to an AWS S3 bucket. And in this tutorial, you’ve learned to copy single and multiple files (entire directory), but there are more ways to customize the file copy process as needed.
At this point, you can already manage your AWS S3 storage efficiently and effectively. So why not try these commands out in your own environment? You can even try to use AWS KMS to secure your S3 files while copying them.


