


If you’ve got many containers to manage, it’s time to automate the management of every containerized application by using Kubernetes. But, before you go implementing Kubernetes, you first need to learn and understand each component of Kubernetes using the Kubernetes architecture diagram.
Kubernetes has many moving pieces, and one of the best ways to understand how each component fits together is with an architecture diagram. In this article, you’re going to learn how each piece fits together as architecture as a whole.
Kubernetes Architecture: High-Level
When organizations find themselves with hundreds or thousands of containers to manage, they soon start to see they need to tool to orchestrate processes on all of those containers. Kubernetes is that tool. In a nutshell, Kubernetes is a container orchestrator.
Kubernetes is a tool, technically a cluster, that watches over all containers to ensure resilient applications running on them. Kubernetes maximizes hardware resources by allocating needed container resources. It also manages features like ensuring all containers are healthy, and if not, repairing them, automatically rolling back botched container changes, and more.
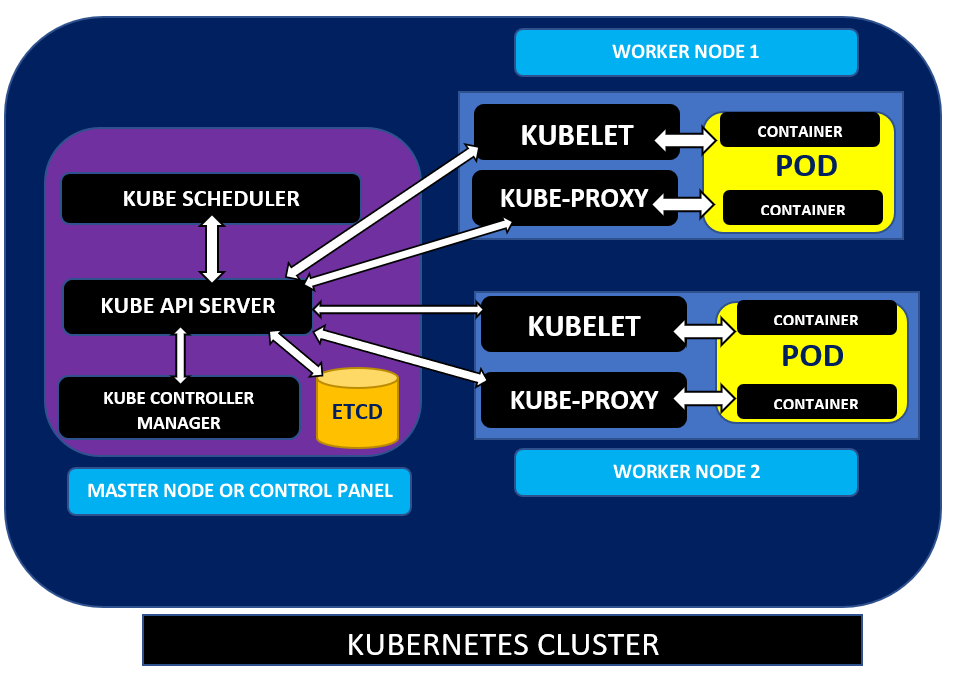
Master Nodes
Inside of a Kubernetes cluster, you’ll find nodes. Nodes are Linux hosts, either virtual machines (VMs) or physical servers, that run various Kubernetes components.
Master nodes, also known as the Control Plane, are the brain of the Kubernetes cluster architecture. Master nodes are the control engine for the Kubernetes cluster that makes all the decisions about the cluster.
Master nodes are responsible for scaling worker nodes, provisioning new container resources, responding to cluster events, and more. It does this through a combination of components internal to each master node.
etcd
As you might have guessed, a Kubernetes cluster has thousands of settings and logic it must maintain. It maintains a highly-available and consistent key-value data store known as etcd to do just that.
Within the etcd datastore, you’ll find cluster information such as the number of pods (more on that later), their state, namespace, etc. Any resource Kubernetes creates is saved in the etcd.
A subset of etcd tracks the state of various attributes throughout the cluster. It does this by holding two types of states; a desired state and a current state. If the master node detects a discrepancy with the two states, it will keep them in sync.
kube-apiserver
A critical part of being a master node is communicating with all of the worker nodes and handling external management requests. To do this, the master node has an API called the kube-apiserver. This API server is the most important component of Master Node.
The kube-apiserver acts as the frontend for the Control Panel and exposes the Kubernetes API. External requests are sent to the API via REST calls, using the kubectl command-line interface, or using other command-line tools such as kubeadm.
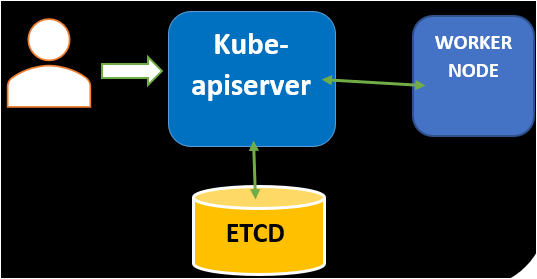
Internally, the kube-apiserver is the only component that all other master and worker components can directly communicate with. The kube-apiserver is also how all the master nodes get access to etcd. It is the communication backbone of the cluster.
The kube-apiserver acts as a go-between between nearly every Kubernetes component. You can see an example below.
Kube-scheduler
Kube-scheduler is responsible for scheduling the pods. First, the Kubernetes scheduler maintains the resource utilization of every worker node, the cluster’s health, load on cluster nodes, etc. Next, it takes the service’s requirements and schedules them on the best fit node.
Kube scheduler considers the health of the cluster, pod’s resource demands, such as CPU or memory, before allocating the pods to the worker node of the cluster. The scheduler runs each time there is a need to schedule pods.
Kube-controller-manager
Kube-controller-manager is yet another important component of the Control Panel that manages applications through various controllers by comparing the cluster’s desired state (also known as spec) with the current state of any applications working on it. Kube-controller-manager checks the current status from etcd through kube-apiserver.
Whenever there is a change in the cluster’s service configuration, for example, replacing the image from which the pods are running, the controller identifies the change and works towards the desired state.
In addition, it contains several controller processes such as node controller, endpoint controller that controls the state of the cluster, endpoints of Pod, and services. Let’s learn them!
There are mainly four types of controller
- Node controller: The node controller is responsible for the monitoring nodes’ status, such as when nodes get up and down.
- Job controller: The job controller is responsible for running the Jobs, which contain various tasks such as creating Pods and running them in specific nodes.
- Replication controller: Replication controller maintains correct number of pods.
- Endpoints controller: Endpoints controller populates the endpoints object, that is, joins Services & Pods.
- Service Account & Token controllers: Creates default accounts and API access tokens for new namespaces.
Worker Nodes
Now it’s time to learn about the workhorses of a Kubernetes cluster, the worker node. The worker nodes are responsible for running workloads. They run the containers and also provide details to the master node(s) like health metrics. The worker nodes carry out instructions given to them by the kube-apiserver.
Worker nodes contain various components, including a Kubelet, Kube-proxy, container runtime, and Node components run on every node, maintaining the details of all running pods.
Pods
In a Kubernetes architecture diagram, you’ll never see a container running directly on a node. Instead, containers always run within pods on worker nodes. Pods can contain one or more containers managed as a single entity and share the pod’s resources.
kubelet
A kubelet is a communication agent installed on each worker node that manages all containers in the pod. The kubelet has various actions it performs such as:
- Maintaining worker node health by making sure that the node communicates with the kube-apiserver and ensureing the containers in a pod are running by validating the states stored in etcd.
- Setting up pod requirements, such as mounting volumes, starting containers, and reporting the pod’s status.
For example, the kube-apiserver typically sends Pod Specs, which the kubelet then validates and manages the container accordingly.
Kube-proxy
Kube-proxy is a networking component that runs on each worker node that forwards traffic to handle network communications both outside and inside the cluster.
Kube-proxy helps in the implementation of Kubernetes services that expose a set of applications running on the Pod. Kube-proxy continuously looks for new services and accordingly creates rules on each node to forward traffic to services and the back-end pods.
Container Runtime
Container Runtime is an important component responsible for providing and maintaining the runtime environment to containers running inside the Pod. The most common container runtime is Docker, but others like containerd or CRI-O may also be possible.
Conclusion
You should know have a great overview understand of each of the main components that make up a Kubernetes cluster. In this article, you learned how each component fits together and hopefully now understand what a typical Kubernetes architecture diagram consists of.
How are you planning on using your newfound Kubernetes knowledge?


