


Data flowing through an application is critical for success, and having a reliable way to store and manipulate that data can be crucial. But what is the reliable way? Google Cloud Platform (GCP) Dataflow with SQL can provide the necessary infrastructure to process your real-time data.
This tutorial will walk through how to set up a simple GCP Dataflow pipeline from start to finish and query the results.
Stay tuned and start to manage data processing quickly!
Prerequisites
Before you dive into this tutorial, you will need an active GCP account with sufficient quotas enabled for Dataflow and BigQuery. The trial version of GCP should be fine for this tutorial.
Creating a Google Cloud Project
A GCP project allows you to set up and manage all your GCP services in one place. For this tutorial, you create a GCP project for your Dataflow pipeline and BigQuery. Creating a new GCP project instead of using an existing one helps you organize everything.
To create a GCP project, follow these steps:
1. Open your favorite web browser, navigate, and log in to your account on the Manage Resources page in the GCP Console.
2. Next, click CREATE PROJECT to initiate creating a new GCP project.

3. On the New Project form, provide a descriptive name, keep other settings as is, and click CREATE to create a GCP project. This tutorial uses the name gcp-dataflow-project, but you can choose a different project name.
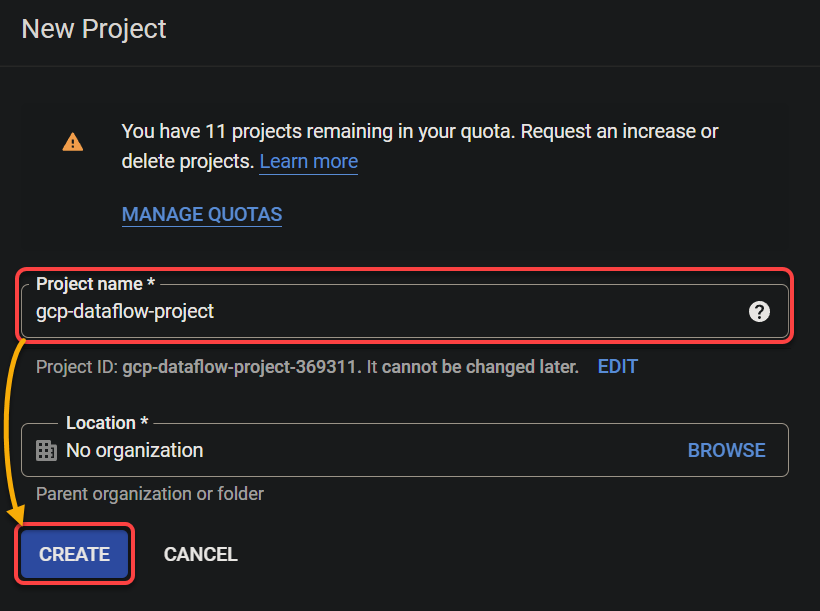
Below, you can see the notification shows the project creation is completed.
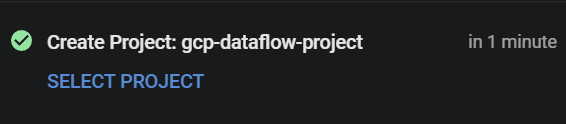
4. Now, navigate to the project selector, and click on the newly-created GCP project to select it.
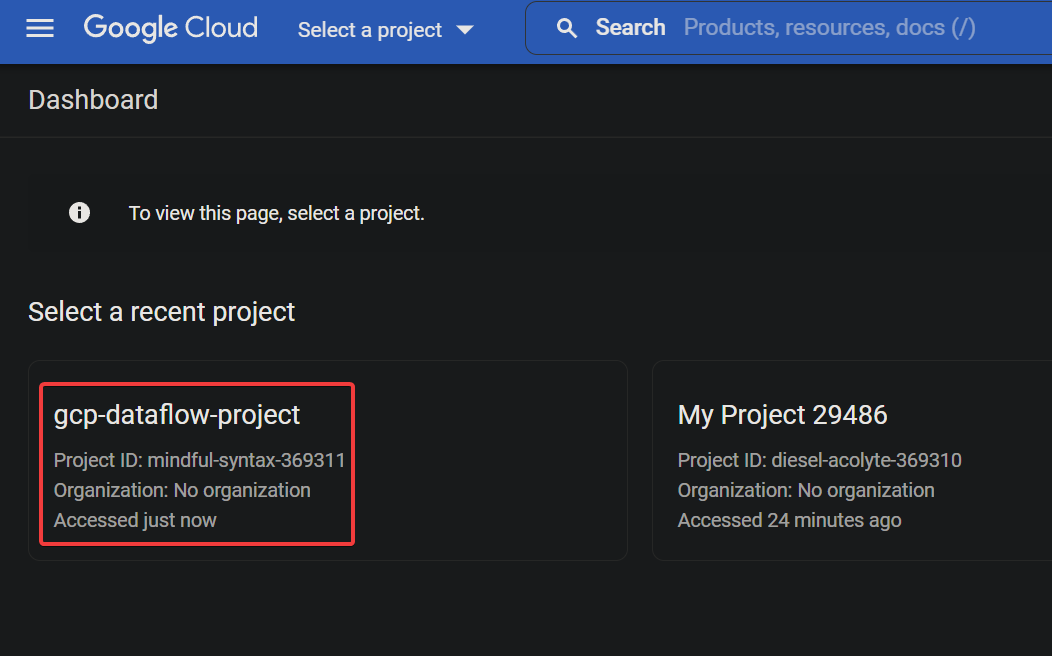
5. Navigate to Enable access to APIs page, and click Next to confirm making changes to your project.
6. Lastly, click ENABLE to enable the APIs for your project, which are required to use GCP Dataflow (Dataflow API) and BigQuery (BigQuery API).
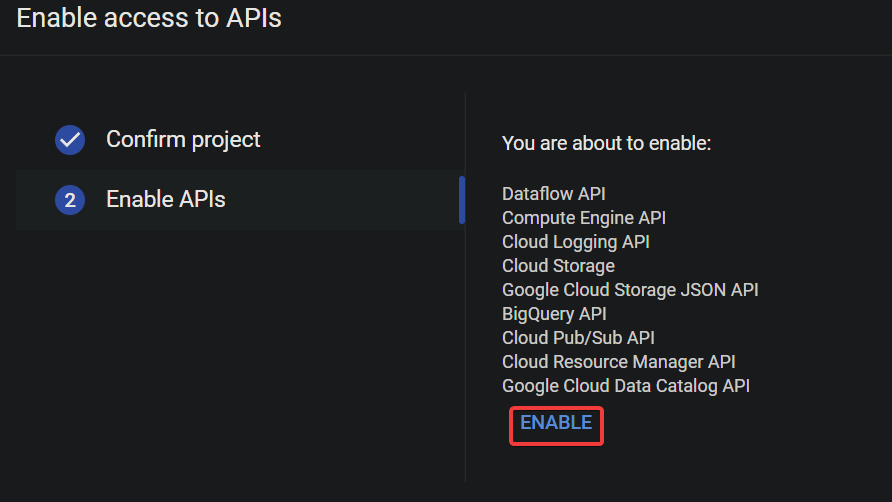
You will see a notification, as shown below, once the APIs are enabled.

Creating a BigQuery Dataset
Google BigQuery is a serverless, highly scalable, and cost-effective data warehouse that can store and analyze petabytes of data. In this tutorial, you will create a simple dataset in BigQuery to store the stream of data flowing through your SQL pipeline.
But first, you need access to Google Cloud Shell, a web-based command-line tool, where you can run commands on your GCP projects.
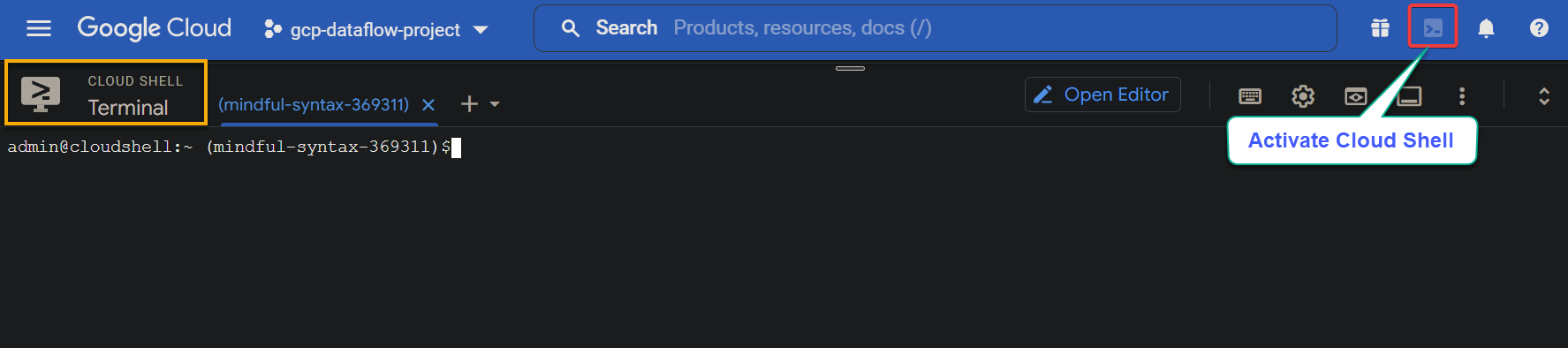
1. Click the Activate Cloud Shell icon (top-right) on the GCP console, as shown below. Doing so launches a new terminal pane from which you can directly run GCP commands.
2. Next, run the following bq mk command in the Cloud Shell to set a dataset name. This tutorial uses gcp_dataflow_taxirides_dataset, but you can name the dataset as you like.
bq mk gcp_dataflow_taxirides_dataset3. Now, click AUTHORIZE when prompted to authorize the bq (BigQuery) command-line tool.
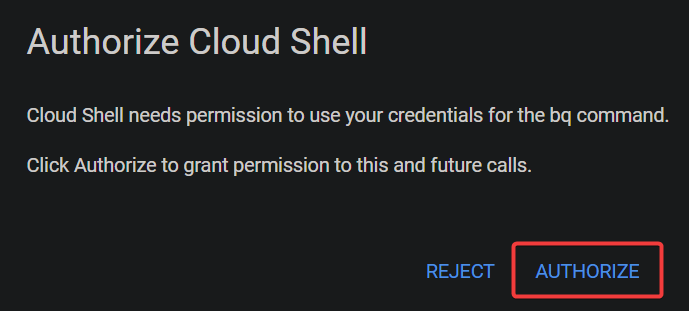
If successful, you will see a screen similar to the one below.

Running a GCP Dataflow SQL Pipeline
Now that you have a BigQuery dataset, you are ready to create a GCP Dataflow pipeline for your project to process data with SQL.
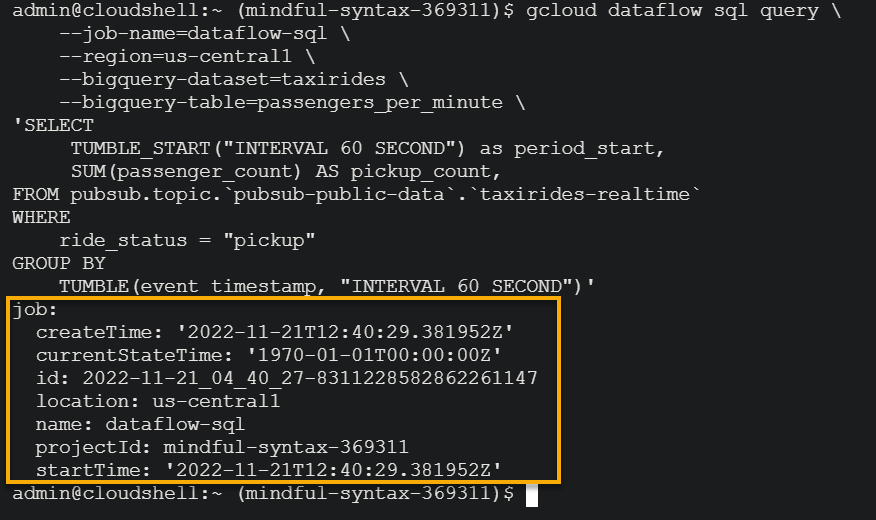
Run the below command to create a Dataflow SQL pipeline for your project. This dataflow pipeline calculates the number of passengers picked up in a specific time period (one minute) from a public GCP Pub/Sub topic.
The following defines your Dataflow SQL pipeline:
| Parameter value | Description |
|---|---|
| dataflow-sql | The job name for your pipeline, which you can change to anything. |
| us-central1 | The region where you will be running your pipeline. |
| taxirides | The BigQuery dataset, which stores the result of the Dataflow SQL query. |
| passengers_per_minute | The BigQuery table, which stores the result of the Dataflow SQL query. |
| taxirides-realtime | The GCP Pub/Sub topic from which you will be streaming data. Google provides many public datasets, and this dataset is one of them. |
gcloud dataflow sql query \\
--job-name=dataflow-sql \\
--region=us-central1 \\
--bigquery-dataset=taxirides \\
--bigquery-table=passengers_per_minute \\
'SELECT
TUMBLE_START("INTERVAL 60 SECOND") as period_start,
SUM(passenger_count) AS pickup_count,
FROM pubsub.topic.`pubsub-public-data`.`taxirides-realtime`
WHERE
ride_status = "pickup"
GROUP BY
TUMBLE(event_timestamp, "INTERVAL 60 SECOND")'Once the job is successful, you will see a similar screen, as shown below.
Verifying the GCP Dataflow SQL Pipeline
You have managed to create your first Dataflow SQL pipeline. But how do you know it is working? Worry not. GCP lets you verify the job run in different views.
Among other job step views, for this example, you will go for the Graph view to see a breakdown of which step took place and when.
Navigate to the Dataflow Jobs page in your GCP console, and click the job name (dataflow-sql) to see the job details.
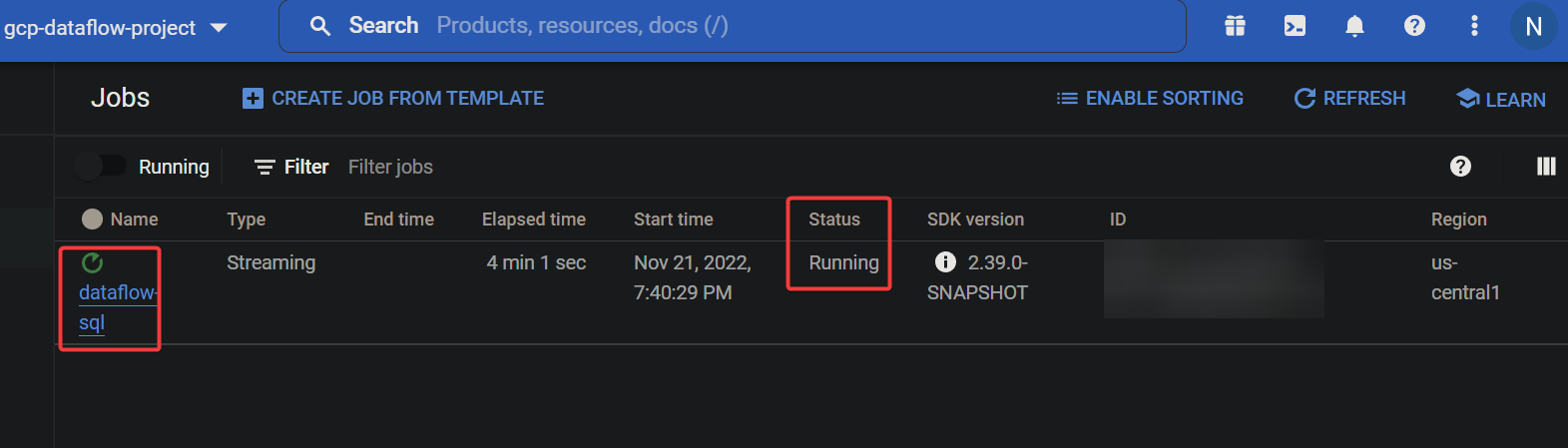
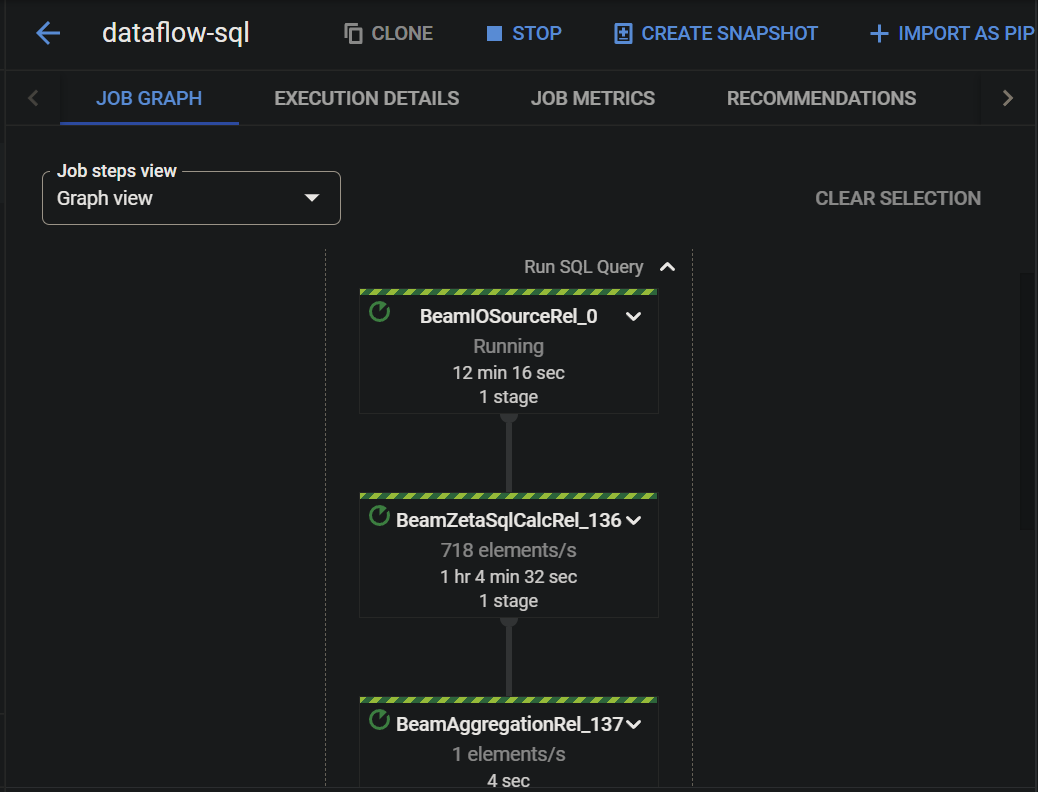
On the Graph view below, you will see the status of every stage of your job. If the stages are completed successfully, the green bar on each stage is full.
Querying Results in BigQuery
Even though the job run was successful, how do you know each stage performed its tasks? With your Dataflow SQL job running, you can query the result table in BigQuery to get the count of passengers picked up in a specific time period (one minute).
1. Navigate to the BigQuery page in the GCP console.
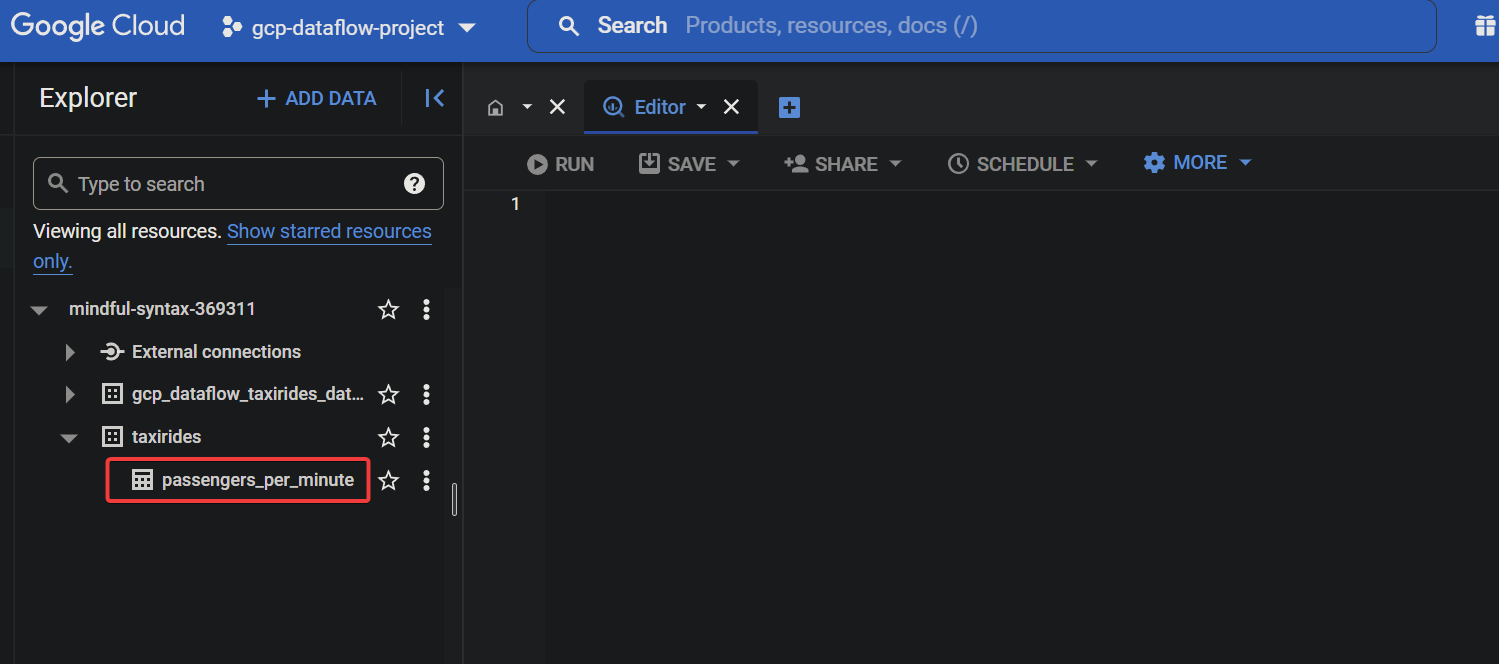
2. Next, look for and click the passengers_per_minute table in the taxirides dataset, as shown below, to find the data populated by the Dataflow SQL pipeline.
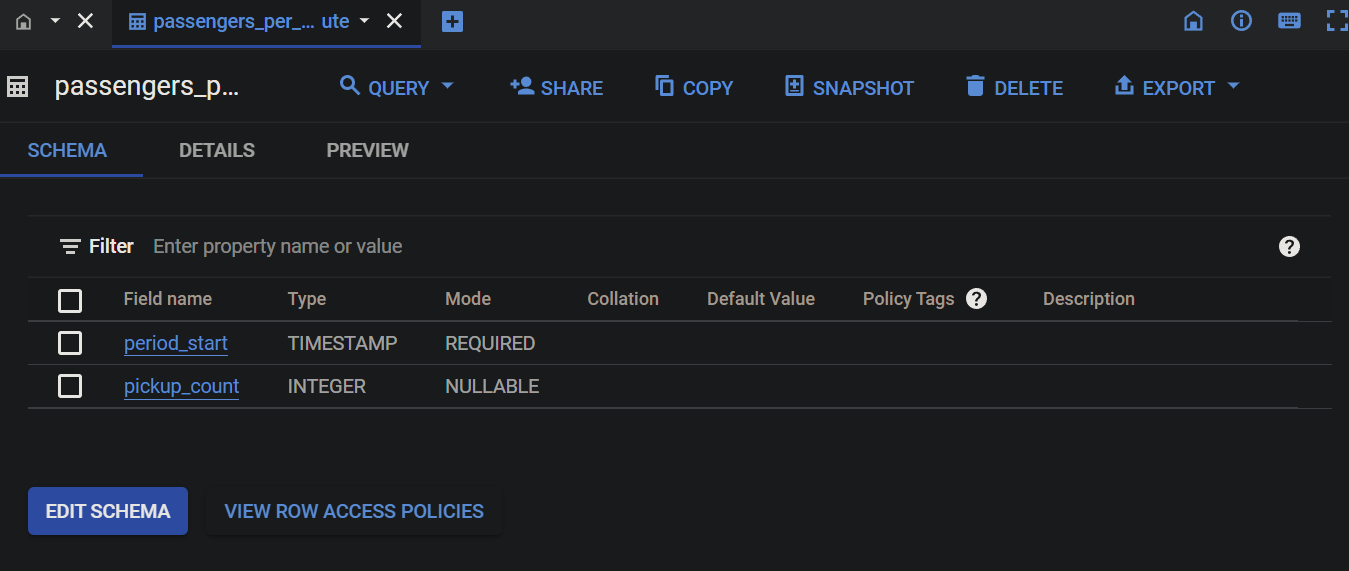
Below, you can see the data your Dataflow SQL pipeline populated
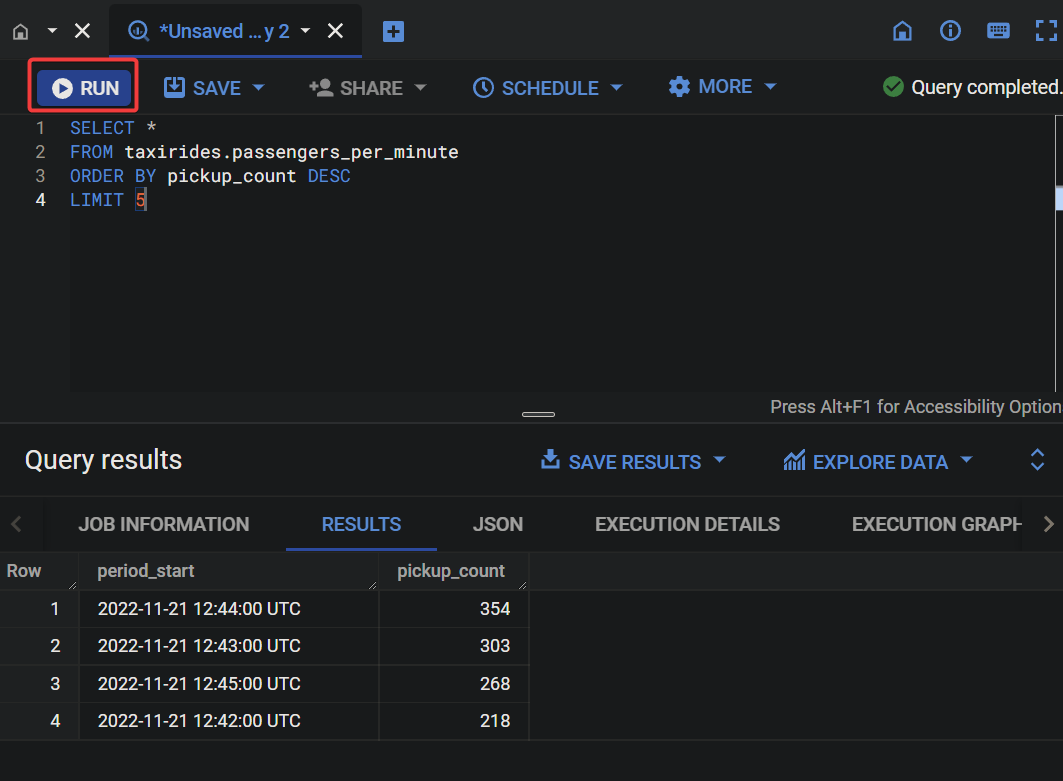
3. Now, copy the following SQL query to the BigQuery query editor, and click RUN to get the passenger pickup counts.
This SQL query gives you the top five results (LIMIT 5) of the Dataflow SQL pipeline, grouped by the minutes and sorted in descending order (DESC).
SELECT *
FROM taxirides.passengers_per_minute
ORDER BY pickup_count DESC
LIMIT 5In the following output, you can see the busiest minute is the first result of this query.
Cleaning Up Resources
You have verified your Dataflow SQL pipeline is running successfully, and the result table in BigQuery contains the expected data. But remember, leaving these resources in place results in incurring charges. Imagine breaking the bank because you left resources running for a pipeline test — traumatic.
To clean up your resources:
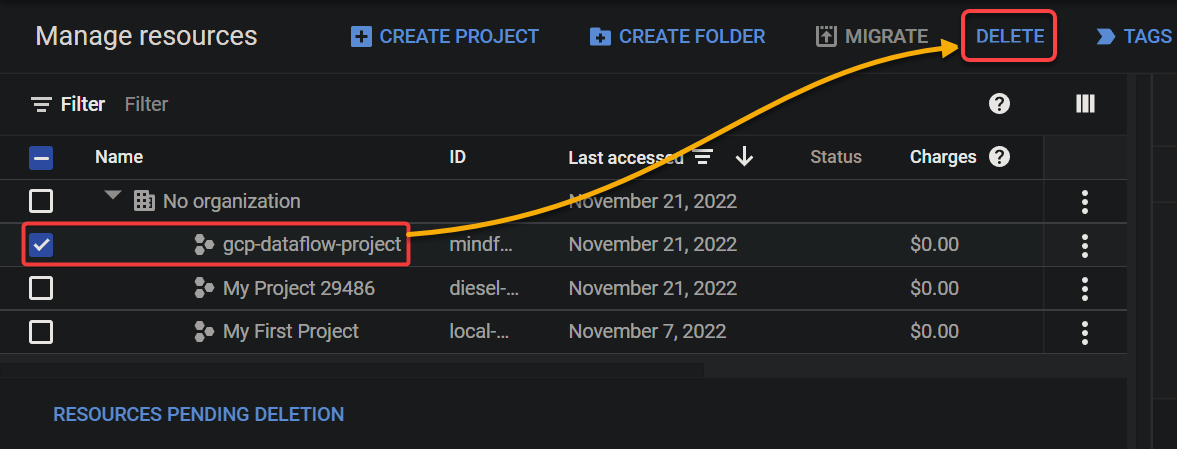
1. Navigate to the Resource Manager page in the GCP console.
2. Next, select your GCP project, and click DELETE to delete the project.
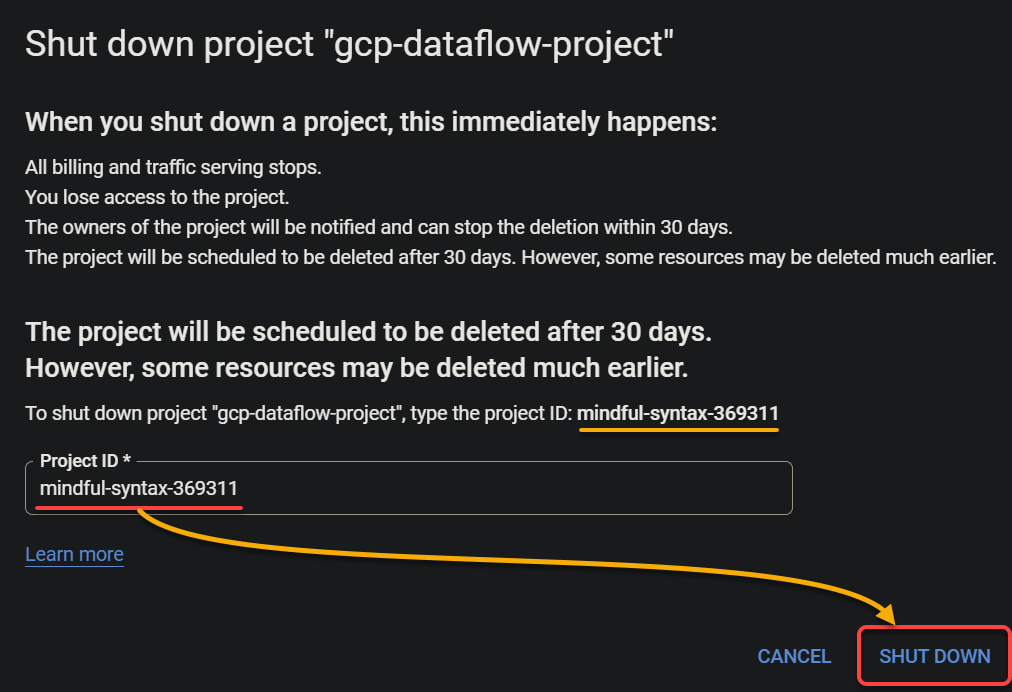
3. Lastly, enter the listed project ID, and click SHUT DOWN to confirm the project deletion.
This action deletes all resources created in your project, including the Dataflow job, BigQuery dataset, and Pub/Sub topic. Note that you will have 30 days grace period to recover this project if you accidentally deleted it.
Conclusion
Data flowing is a powerful tool that allows you to process data quickly and efficiently. And in this tutorial, you have learned to create a basic Google Dataflow SQL pipeline using GCP tools and verify the results.
With this knowledge, you can now scale up data processing using Google Cloud Platform leading to faster insights into your data. Why not use parameterized Dataflow SQL queries for more complex data processing tasks? Explore and make the most of GCP-Dataflow SQL!


