


If you’re tired of your Bash scripts taking forever to run, this tutorial is for you. Often, you can Bash scripts in parallel, which can dramatically speed up the result. How? Using the GNU Parallel utility, also just called Parallel, with some handy GNU Parallel examples!
Parallel executes Bash scripts in parallel via a concept called multi-threading. This utility allows you to run different jobs per CPU instead of only one, cutting down on time to run a script.
In this tutorial, you’re going to learn multi-threading Bash scripts with a ton of great GNU Parallel examples!
Prerequisites
This tutorial will be full of hands-on demonstrations. If you intend to follow along, be sure you have the following:
- A Linux computer. Any distribution will work. The tutorial uses Ubuntu 20.04 running on Windows Subsystem for Linux (WSL).
- Logged-in with a user with sudo privileges.
Installing GNU Parallel
To begin speeding up Bash scripts with multithreading, you must first install Parallel. So let’s get started by downloading and getting it installed.
1. Open a Bash terminal.
2. Run wget to download the Parallel package. The command below downloads the latest version (parallel-latest) into the current working directory.
wget https://ftp.gnu.org/gnu/parallel/parallel-latest.tar.bz2If you’d rather use an older version of GNU Parallel, you can find all packages at the official download site.
3. Now, execute the tar command below to un-archive the package you just downloaded.
Below, the command uses the x flag to extract the archive, j to specify that it targets an archive with a .bz2 extension, and f to accept a file as the input to the tar command. sudo tar -xjf parallel-latest.tar.bz2
sudo tar -xjf parallel-latest.tar.bz2You should now have a directory named parallel- with the month, day and year of the latest release.
4. Navigate into the package archive folder with cd. In this tutorial, the package archive folder is called parallel-20210422, as shown below.
5. Next, build and install the GNU Parallel binary by running the following commands:
./configure
make
make installNow, verify that Parallel installed correctly by checking the version that’s installed.
parallel --version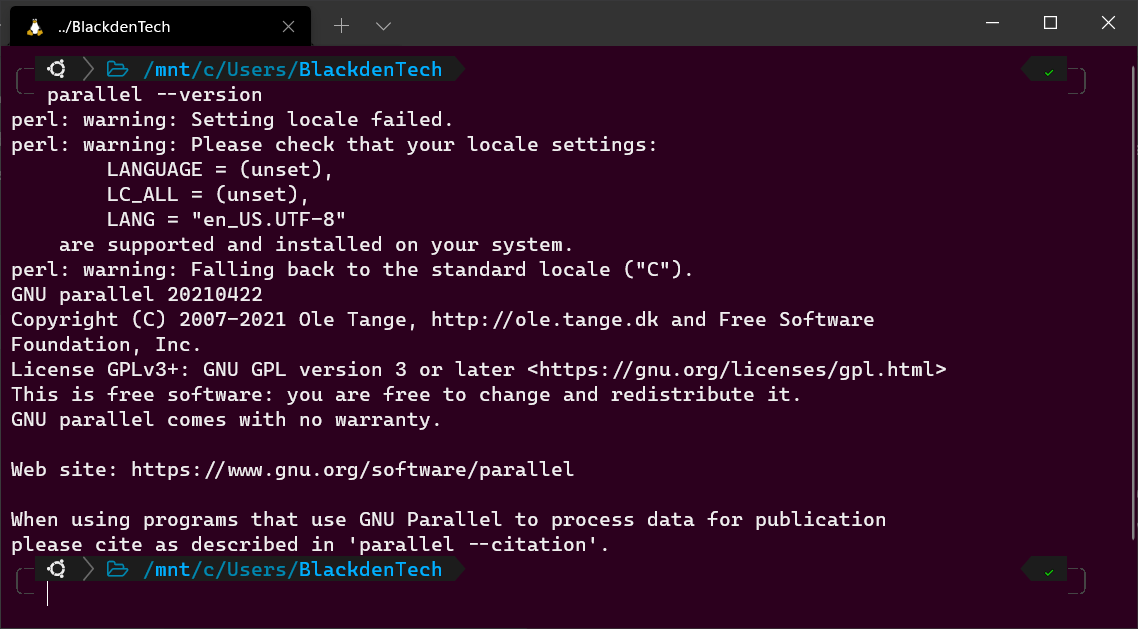
When running Parallel for the first time, you might also see a couple of scary lines that display text like
perl: warning:. Those warning messages indicate that Parallel can’t detect your current locale and language settings. But don’t worry about those warnings for now. You’ll learn how to fix those warnings later.
Configuring GNU Parallel
Now that Parallel is installed, you can use it right away! But first, it’s important to configure a few minor settings before getting started.
While still in your Bash terminal, agree to the GNU Parallel academic research permission telling Parallel that you will cite it in any academic research by specifying the citation parameter followed by will cite.
If you do not want to support GNU or it’s maintainers, agreeing to cite is not required to use GNU Parallel.
parallel --citation
will citeChange the locale by setting the following environment variables by running the lines of code below. Setting locale and language environment variables like this isn’t a requirement. But GNU Parallel checks for them every time it runs.
If the environment variables do not exist, Parallel will complain about them every time as you saw in the previous section.
This tutorial assumes that you are an English speaker. Other languages are supported as well.
export LC_ALL=C man
export LANGUAGE=en_US
export LANG=en_US.UTF-8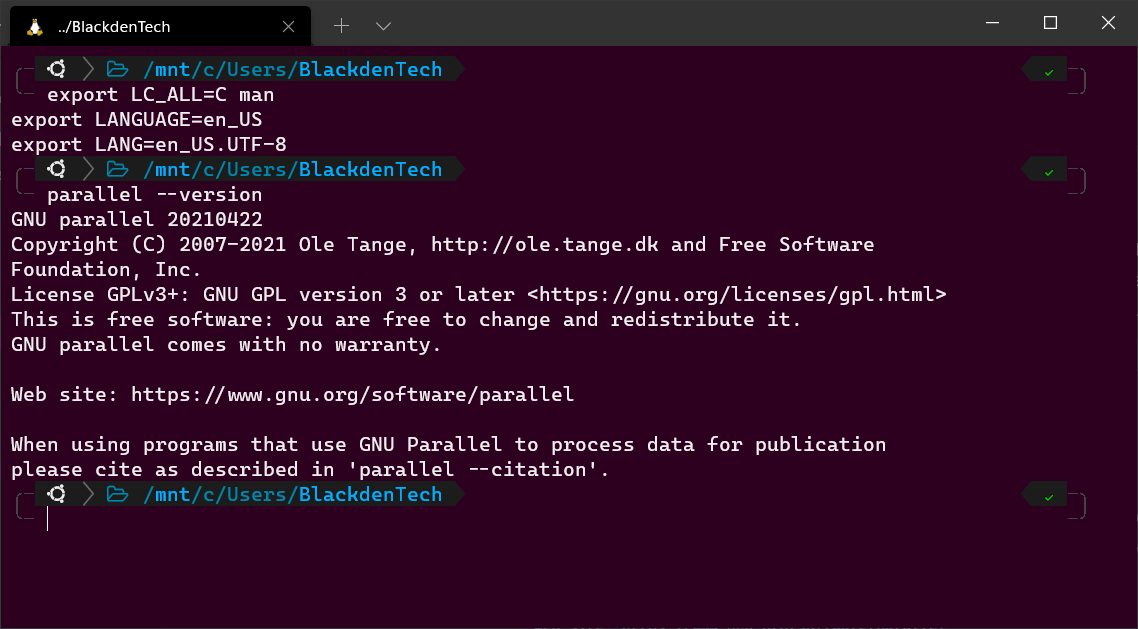
Running Ad-Hoc Shell Commands
Let’s now get started using GNU Parallel! To start with, you’ll learn the basic syntax. Once you’re comfortable with the syntax, you’ll then get into some handy GNU Parallel examples later on.
To begin, let’s cover a super-simple example of just echoing the numbers 1-5.
1. In your Bash terminal, run the following commands. Exciting, right? Bash uses the echo command to send the numbers 1-5 to the terminal. If you’d put each of these commands in a script, Bash would execute each one sequentially, waiting for the previous one to finish.
In this example, you are executing five commands that don’t take hardly any time. But, imagine if those commands were Bash scripts actually did something useful but took forever to run?
echo 1
echo 2
echo 3
echo 4
echo 5Now, run each of those commands in at the same time with Parallel like below. In this example, Parallel runs the echo command and designated by the :::, passes that command the arguments, 1, 2, 3, 4, 5. The three colons tell Parallel that you’re providing input via the command line rather than the pipeline (more later).
In the below example, you passed a single command to Parallel with no options. Here, like all Parallel examples, Parallel started a new process for each command using a different CPU core.
# From the command line
parallel echo ::: 1 2 3 4 5All Parallel commands follow the syntax
parallel [Options] <Command to multi-thread>.
3. To demonstrate Parallel receiving input from the Bash pipeline, create a file called count_file.txt like below. Each number represents the argument you will pass to the echo command.
1
2
3
4
54. Now, run the cat command to read that file and pass the output to Parallel, as shown below. In this example, the {} represents each argument (1-5) that will be passed to Parallel.
# From the pipeline cat count_file.txt | parallel echo {}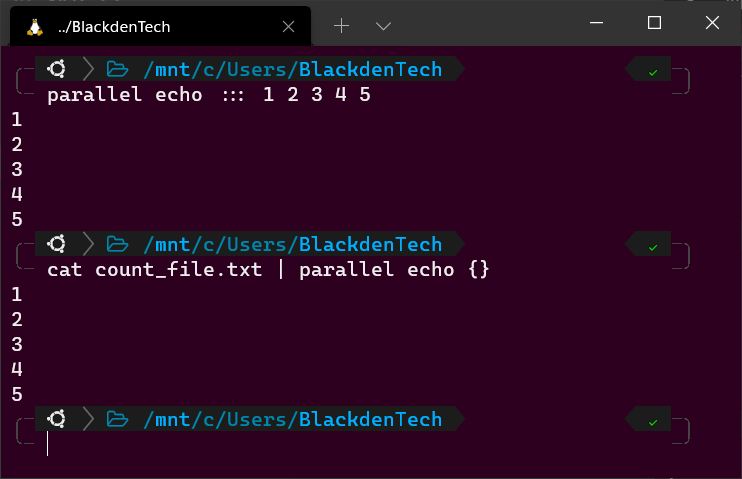
Comparing Bash and GNU Parallel
Right now, using Parallel might just seem like a complicated way to run Bash commands. But the real benefit to you is time savings. Remember, Bash will run on only one CPU core while GNU Parallel will run on several at once.
1. To demonstrate the difference in sequential Bash commands vs. Parallel, create a Bash script called test.sh with the following code. Create this script in the same directory you created the count_file.txt in earlier.
The Bash script below reads the count_file.txt file, sleeps for 1, 2, 3, 4, and 5 seconds, echos the sleep length to the terminal, and terminates.
#!/bin/bash
nums=$(cat count_file.txt) # Read count_file.txt
for num in $nums # For each line in the file, start a loop
do
sleep $num # Read the line and wait that many seconds
echo $num # Print the line
done2. Now, run the script using the time command to measure how long the script takes to complete. It will take 15 seconds.
time ./test.sh3. Now, use the time command again to perform the same task but this time use Parallel to do so.
The command below performs the same task but this time, instead of waiting for the first loop to complete before starting the next, it will run one on each CPU core, and start as many as it can at the same time.
time cat count_file.txt | parallel "sleep {}; echo {}"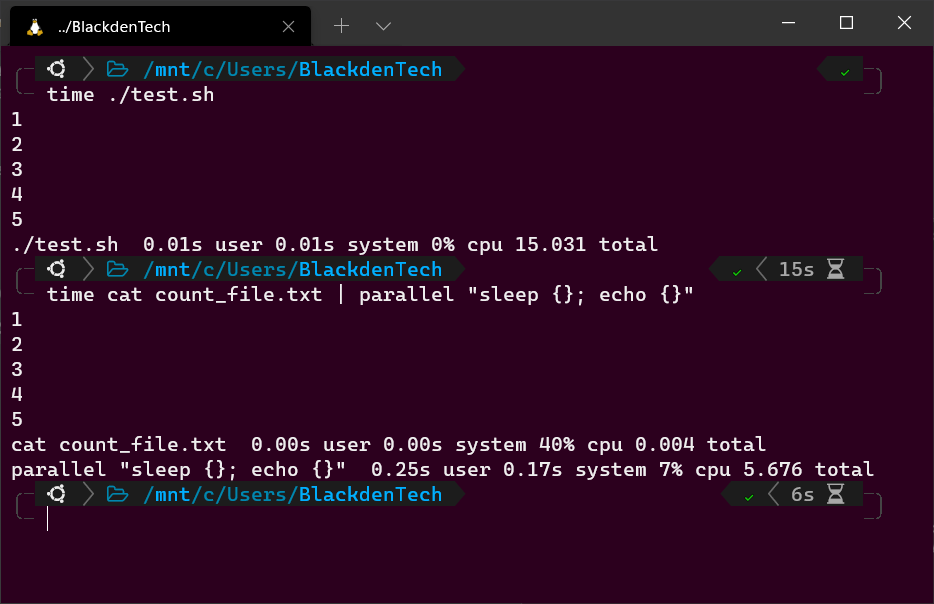
Know the Dry Run!
It’s now time to get into some more real-world GNU Parallel examples. But, before you do, you should first know about the --dryrun flag. This flag comes in handy when you want to see what will happen without Parallel actually doing it.
The --dryrun flag can be the final sanity check before running a command that doesn’t behave the way you thought. Unfortunately, if you enter a command that would harm your system, the only thing GNU Parallel will help you do is harm it faster!
parallel --dryrun "rm rf {}"GNU Parallel Example #1: Downloading Files from the Web
For this task, you will download a list of files from various URLs on the web. For example, these URLs could represent web pages you want to save, images, or even a list of files from an FTP server.
For this example, you’re going to download a list of archive packages (and the SIG files) from GNU parallel’s FTP server.
1. Create a file called download_items.txt, grab some download links from the official download site and add them to the file separated by a new line.
https://ftp.gnu.org/gnu/parallel/parallel-20120122.tar.bz2
https://ftp.gnu.org/gnu/parallel/parallel-20120122.tar.bz2.sig
https://ftp.gnu.org/gnu/parallel/parallel-20120222.tar.bz2
https://ftp.gnu.org/gnu/parallel/parallel-20120222.tar.bz2.sigYou could save some time by using Python’s Beautiful Soup library to scrape all of the links from the download page.
2. Read all of the URLs from the download_items.txt file and pass them to Parallel, which will invoke wget and pass each URL.
cat download_items.txt | parallel wget {}Don’t forget that
{}in a parallel command is a placeholder for the input string!
3. Perhaps you need to control the number of threads that GNU Parallel uses at once. If so, add the --jobs or -j parameter to the command. The --jobs parameter limits the number of threads that can run concurrently to the number you specify.
For example, to limit Parallel to downloading five URLs at a time, the command would look like this:
#!/bin/bash
cat download_items.txt | parallel --jobs 5 wget {}The
--jobsparameter in the above command can be adjusted to download any number of files, so long as the computer, you are running on has that many CPUs to process them.
4. To demonstrate the effect of the --jobs parameter, now adjust job count and run the time command to measure how long each run takes.
time cat download_items.txt | parallel --jobs 5 wget {}
time cat download_items.txt | parallel --jobs 10 wget {}GNU Parallel Example #2: Unzipping Archive Packages
Now that you have all of these archive files downloaded from the previous example, you must now un-archive them.
While in the same directory as the archive packages, run the following Parallel command. Notice the use of the wildcard (*). Since this directory contains both archive packages and the SIG files, you must tell Parallel to only process .tar.bz2 files.
sudo parallel tar -xjf ::: *.tar.bz2Bonus! If you are using GNU parallel interactively (not in a script), add the --bar flag to have Parallel show you a progress bar while the task is running.
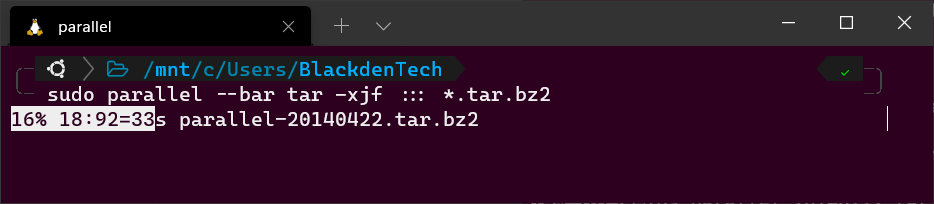
--bar flagGNU Parallel Example #3: Removing Files
If you’ve followed examples one and two, you should now have many folders in your working directory taking up space. So let’s remove all of those files in parallel!
To remove all folders that start with parallel- using Parallel, list all of the folders with ls -d and pipe each of those folder paths to Parallel, invoking rm -rf on each folder, as shown below.
Remember the
--dryrunflag!
ls -d parallel-*/ | parallel "rm -rf {}"Conclusion
Now you can automate tasks with Bash and save yourself a lot of time. What you choose to do with that time is up to you. Whether saving time means leaving work a little early or reading another ATA blog post, it’s time back in your day.
Now think about all of the long-running scripts in your environment. Which ones can you speed up with Parallel?


