


Data is the lifeblood of every company, and in a machine learning setting, data is generated from several sources. Data cleaning is crucial for a machine learning setting to work correctly. But how do you perform data cleaning? Data cleaning Python tools are just what you need!
In this tutorial, you will learn what data cleaning is and how to clean data with Python tools so that you can enjoy fresh and clean data.
Prerequisites
This tutorial will be a hands-on demonstration. If you’d like to follow along, be sure you have the following:
- A Window or Linux machine – This tutorial uses Windows 10 21H1 Build 19043.
- Jupyter Lab (version 3.12.1 is used in this tutorial) and Python 3 or higher.
- Download the Pokémon dataset to use for the demos.
Importing Data Cleaning Python Pandas Library
Python has several built-in libraries to help with data cleaning. The two most popular libraries are pandas and numpy, but you’ll be using pandas for this tutorial. Pandas library allows you to work with pandas dataframe for data analysis and manipulation.
Before you can perform data cleansing with Python pandas, import the pandas library and your dataset (CSV file) first:
Launch your JupyterLab, and then drag and drop the Pokémon dataset into your JupyterLab.
Now, run the below commands in sequence to read the dataset and display a preview of the data, so you can check if you have any import errors.
# Import the pandas library and set pd as the standard way
# to reference pandas.
import pandas as pd
# Read the data from the dataset into your pandas dataframe.
data = pd.read_csv("pokemon.csv")
# Display a preview of the data.
data.head()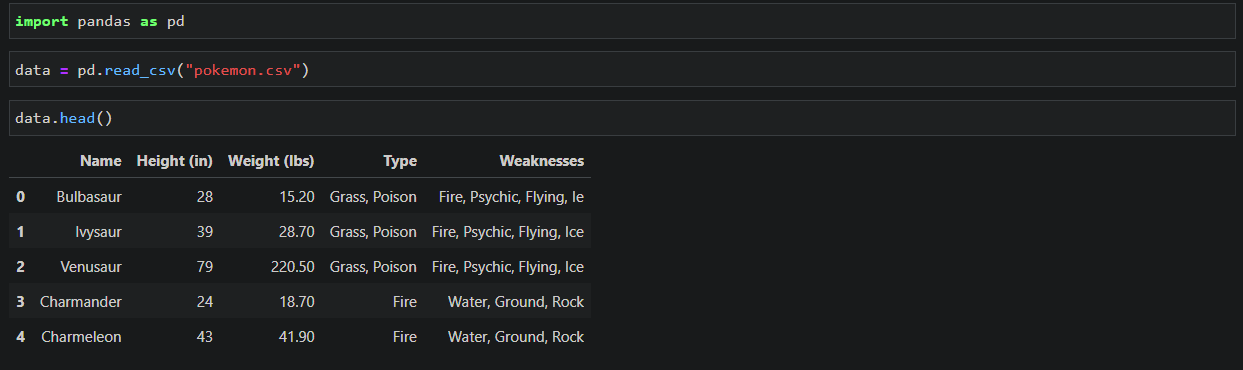
Removing Whitespaces in Datasets
Now that you’ve imported your dataset, you can start cleaning your data. There are many ways to clean your dataset, like removing whitespaces. Whitespaces unnecessarily increase the size of your dataset in your database and make finding duplicate data a challenge.
1. Check your dataset if there are whitespaces like what you see in the Name, Type, and Weaknesses columns below. You’ll remove these irrelevant parts of the data systematically.

2. Copy and paste the following codes to your code shell, and press Shift+Enter keys to execute the code. The code below passes the column name to the replace() function to remove leading and trailing whitespaces in your dataset.
# remove whitespaces from Name column
data["Name"].str.replace(' ', '')
# remove whitespaces from Weight column
data["Type"].str.replace(' ', '')
# remove whitespaces from Type column
data["Weaknesses"].str.replace(' ', '')3. Finally, check your dataset again to confirm the whitespaces are gone similar to the one below.

Removing Duplicate Values
Whitespaces is not the only one you’ll need to look out for in a dataset. With tons of data in your dataset, you may have overlooked some duplicates. So what’s the process of detecting and removing duplicates? You’ll first look for duplicates by column name in your dataset and remove them.
Each entry in your dataset should have unique data under the Name column. But as you can see below, Blastoise has two entries, one at row 10 and another one at row 11. Since the Height column should only contain numbers, you’ll remove the entry at row 11, which has the excess inches text in its Height column.
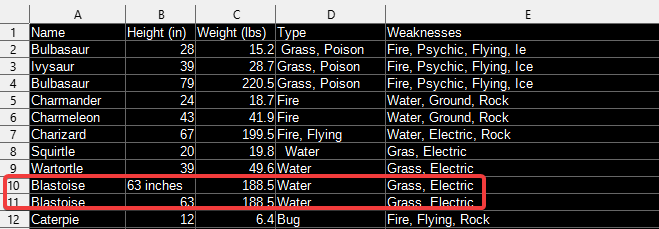
Run the following commands to remove the first duplicate data.drop_duplicates and keep the last (keep="last") occurrence.
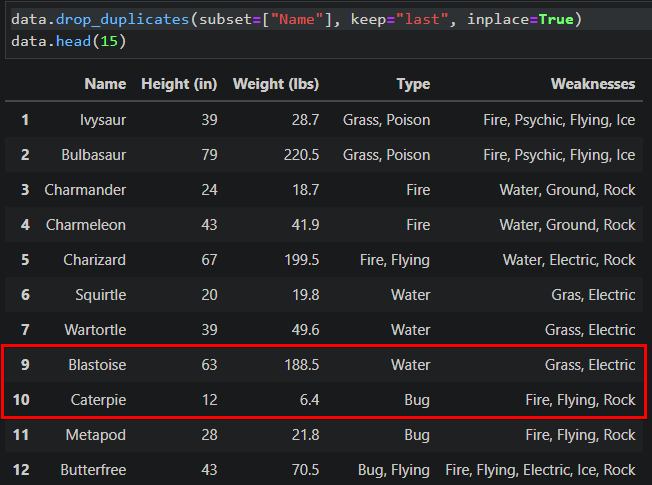
data.drop_duplicates(subset=["Name"], keep="last", inplace=True)
data.head(15)As you can see below, the duplicate on row 10 is now gone, so you don’t have to worry about fixing that excess “inches” string anymore.
Filling in the Missing Values
So far, you’ve tackled removing excess data (whitespaces and duplicates), but what about missing data? With the data.info() command, you can check columns with missing data in your dataset.
From this point, filling in the missing data is crucial, or else you’ll get an error when running commands in the following sections.
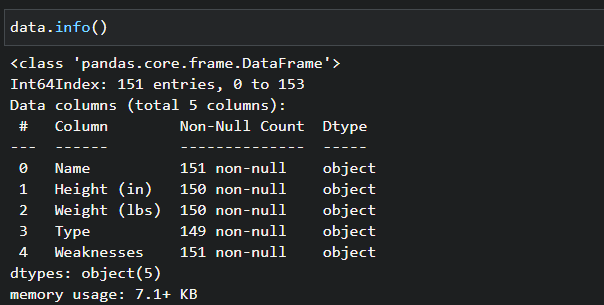
1. Run the data.info() command below to check for missing values in your dataset.
data.info()There’s a total of 151 entries in the dataset. In the output shown below, you can tell that three columns are missing data. Both the Height and Weight columns have 150 entries, and the Type column only has 149 entries.
2. Next, run the following command to show all entries with at least one (.any(axis=1)) missing data data.isnull().
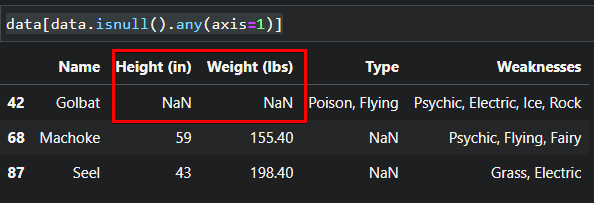
data[data.isnull().any(axis=1)]Notice below that the Height, Weight, and Type columns have the Not a Number (NaN) value. The NaN values indicate the columns have null or missing data.
In the output below, you can see Golbat is missing Height and Weight data that you’ll fill in on the next step, so be sure to note Golbat’s entry number (42).
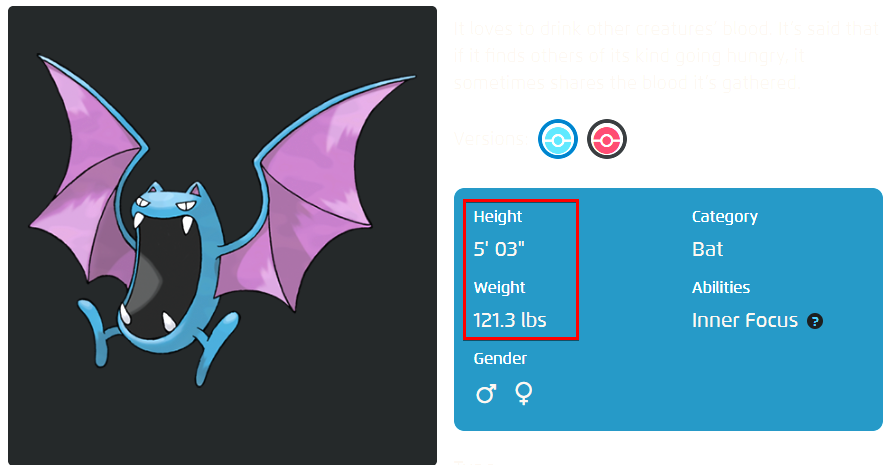
3. Look for Golbat’s information on the Pokémon website on your web browser. In Golbat’s data below, you can see the Height value is 5′ 03″ (63 inches), while the Weight value is 121.3 lbs. Note the height and weight value to fill in the missing data for Golbat in your dataset.
Now, run the following commands to fill Golbat’s missing data in your dataset.
The same set of commands apply to modifying existing values in the dataset
# Pass in ID number (Golbat's entry number=42)
golbat = data.loc[42]
# Sets the Height Value
golbat["Height (in)"] = 63
# Sets the Weight
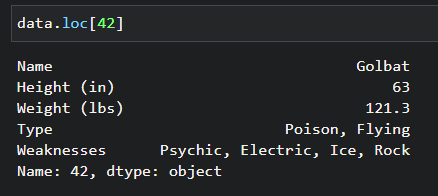
golbat["Weight (lbs)"] = 121.305. Run the data.loc[] command below, where 42 is the entry’s ID number, to list the entry’s data and check any empty values.
data.loc[42]Below, you can see that Golbat’s data are all filled in completely.
After filling in the missing data and there is still at least one element missing, you should remove the entire row that’s missing data from the dataset.
6. Finally, repeat the same steps (three to five) to fill in the missing data for other entries.
Fixing Formatting Errors
Instead of missing data, another typical scenario in a dataset is formatting errors. Inaccurate records can be a pain, but no worries, you can still fix them up!
Perhaps you have an entry in your data set with words separated by dashes like the one below instead of commas and spaces. If so, running the apply() and replace() commands will do the trick.
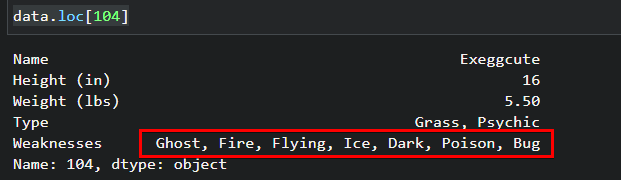
1. Run the command below to see how the data looks in your dataframe. Replace the 104 with the entry number of the data with a formatting error.
data.loc[104]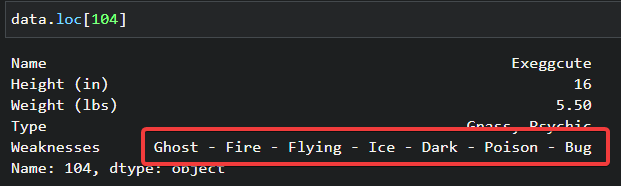
2 Next, run the command below to replace dashes with commas (lambda x: x.replace(" -", ",")) in the data entry’s Weaknesses (data["Weaknesses"]) column.
data["Weaknesses"] = data["Weaknesses"].apply(lambda x: x.replace(" -", ","))3. Rerun the data.loc[104] command as you did in step one to check for any dashes in the data.
data.loc[104]As you can see below, the output shows commas now separate the words.
Correcting Misspelled Words
Besides formatting errors, misspelled words in a dataset can also make it hard to analyze data. The good news is that you can use some ready-made spell-checker Python libraries. But since you already have pandas installed, you don’t have to worry about installing anything else.
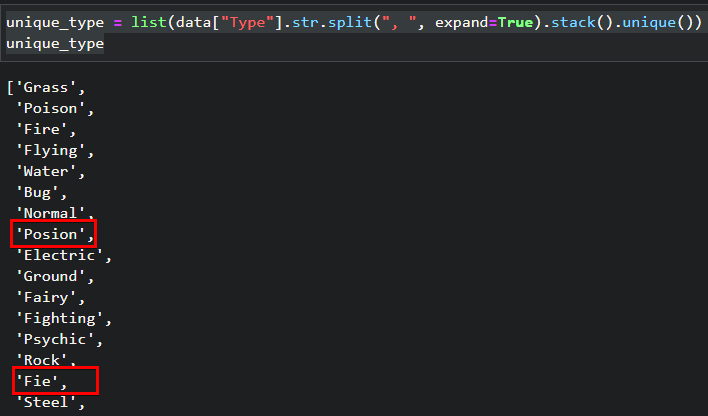
1. Run the following commands to list all unique words unique() in the Type column. Replace Type if you prefer to list unique words from other columns.
# Turn output into a list of unique words from the Type column
unique_type = list(data["Type"].str.split(", ", expand=True).stack().unique())
# Print out the list
unique_typeAs you can see below, there are two misspelled words (Posion and Fie) that should be “Poison” and “Fire.” Now you can go through the dataset, find which rows have misspelled words, and fix them.
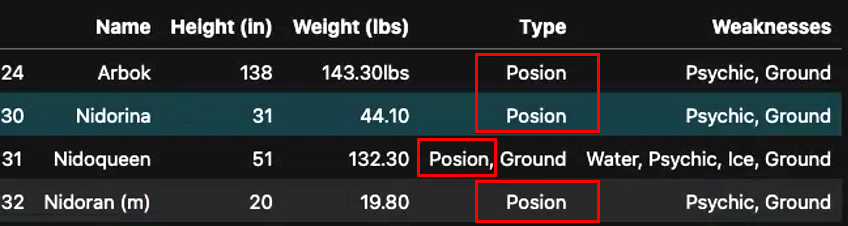
Run the below command to show all rows that contains() the word Posion from the Type column. The regex argument is set to false (regex=False) to treat the string (Posion) as a literal string and not a regular expression.
data[data["Type"].str.contains("Posion", regex=False)]In the following output, there are four rows (Arbok(24), Nidorina(30), Nidoqueen(30) and Nidoran(32)), that have the misspelled word Posion in the Type column.
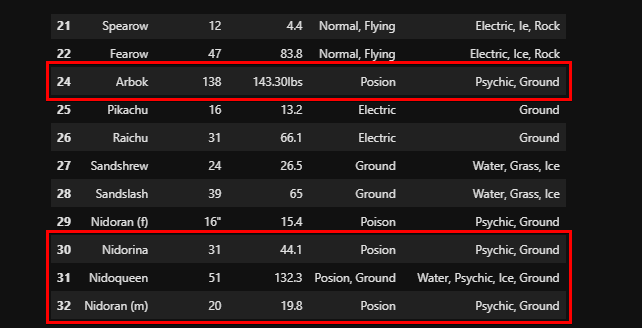
3. Now, run the commands below to replace Posion for all entries in the Type column with the word Poison.
# Replace Posion with the word Poison
data["Type"] = data["Type"].apply(lambda x: x.replace("Posion", "Poison"))
# Lists data entries from 0-30
data.head(30)
If the replacement is successful, you’ll see you’ve corrected the misspelled words from “Posion” to “Poison” in entry numbers 24 and 30-32.
4. Finally, repeat the steps (two to three) to correct other misspelled words.
Conclusion
In this tutorial, you’ve learned how to perform data cleaning with Python in many ways for different use cases. You’ve also come to realize that pandas, a popular Python library, is just right around the corner to let you save time cleaning data.
With this newfound knowledge, why not learn more about handy pandas techniques in Python for data manipulation?


