


If you’ve built an Azure DevOps Pipeline as your solution to a CI/CD pipeline, you’ve undoubtedly run across situations that require dynamically managing configuration values in builds and releases. Whether it’s providing a build version to a PowerShell script, passing dynamic parameters to build tasks or using strings across build and releases, you need variables.
If you’ve ever asked yourself questions like:
- How do I use Azure DevOps build Pipeline variables in a PowerShell script?
- How do I share variables across builds and releases?
- How do predefined, user-defined and secret variables differ?
- How do variable groups work?
…then you’re in luck! In this article, we will answer each of these questions and more.
By the end of this article, you will understand how Azure DevOps build variables work in Azure Pipelines!
What are Azure DevOps Pipeline Variables?
Before we dive into the specifics of variables, what are they and how do they help you build and automate efficient build and release pipelines?
Variables allow you to pass bits of data into various parts of your pipelines. Variables are great for storing text and numbers that may change across a pipeline’s workflow. In a pipeline, you can set and read variables almost everywhere rather than hard-coding values in scripts and YAML definitions.
Note: This article will focus only on YAML pipelines. We will not cover any information about legacy classic pipelines. Also, with a few minor exceptions, you will not learn how to work with variables via the web UI. We will be sticking strictly to YAML.
Variables are referenced and some defined (see user-defined variables) at runtime. When a pipeline initiates a job, various processes manage these variables and pass their values to other parts of the system. This system provides a way to run pipeline jobs dynamically without worrying about changing build definitions and scripts every time.
Don’t worry if you don’t grok the concept of variables at this point. The rest of this article will teach you everything you need to know.
Variable Environments
Before jumping into the variables themselves, it’s first important to cover Azure pipeline variable environments. You’ll see various references to this term throughout the article.
Within a pipeline, there are two places informally called environments where you can interact with variables. You can either work with variables within a YAML build definition called the pipeline environment or within a script executed via a task called the script environment.
The Pipeline Environment
When you’re defining or reading build variables from within a YAML build definition, this is called the pipeline environment. For example, below you can see the variables section defined in a YAML build definition setting a variable called foo to bar. In this context, the variable is being defined within the pipeline environment
variables:
foo: 'bar'The Script Environment
You can also work with variables from within code defined in the YAML definition itself or in scripts. When you don’t have an existing script already created, you can define and read variables within the YAML definition as shown below. You’ll learn the syntax on how to work with these variables in this context later.
steps:
- bash: ## Setting and getting variables in hereYou could alternatively stay within the script environment by adding this same syntax into a Bash script and executing it. This is the same general concept.
Environment Variables
Within the script environment, when a pipeline variable is made available, it’s done so by creating an environment variable. These environment variables can then be accessed via the language of choice’s typical methods.
Pipeline variables exposed as environment variables will always be upper-cased and any dots replaced with underscores. For example, you’ll see below how each scripting language can access the foo pipeline variable as shown below.
variables:
foo: 'bar'- Batch –
%FOO% - PowerShell –
$env:FOO - Bash script –
$FOO
Pipeline “Execution Phases”
When a pipeline “runs”, it doesn’t just “run”. Like the stages it contains, a pipeline also undergoes various phases when it executes. Due to the lack of official term in the Microsoft documentation, I’m calling this “execution phases”.
When a pipeline is triggered, it goes through three rough phases – Queue, Compile and Runtime. It’s important to understand these contexts because if you’re navigating the Microsoft docs, you’ll see references to these terms.
Queue Time
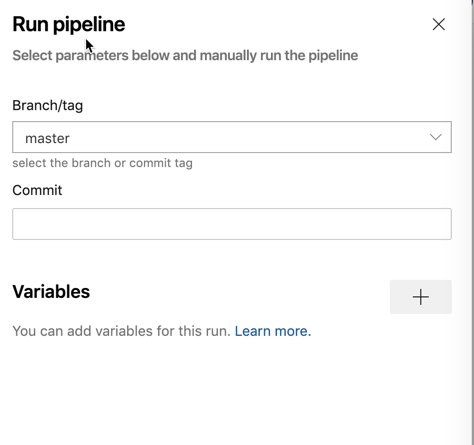
The first phase a pipeline goes through when triggered in queued. In this phase, the pipeline hasn’t started yet but is queued up and ready to go when the agent is available. When defining variables, you can set them to be made available at queue time by not defining them in the YAML file.
You’ll be able to define variables at queue time when the pipeline is initially queued as shown below. When this variable is added, it will then be made available a global variable in the pipeline and can be overridden by the same variable name in the YAML file.
Compile
Finally, when a pipeline processes a YAML file and gets down to the steps that require script execution, the pipeline is in the compile “phase”. In this context, the agent is executing the code defined in the script steps.
Runtime
The next phase is runtime. This is the phase when the YAML file is being processed. During this phase, each stage, job, and step are being processed but not running any scripts.
Variable Expansion
Another important topic to understand is variable expansion. Variable expansion, in simplest terms, is when the variable returns a static value. The variable expands to reveal the value it’s holding. This is done for you with no effort when you read a variable but that expansion can be done at different times during a pipeline run that might trip you up.
This concept of variable expansion and compile vs. runtime will come up a lot when you get into understanding variable syntax.
As you learned above, the pipeline covers different “phases” when it runs. You’ll need to be aware of these phases most likely when troubleshooting variable expansion.
You can see an example below. The concept of these “phases” is closely related to variable environments.
steps:
# Sets FOO to be "some value" in the script and the next ones
- bash: |
FOO="runtime value"
echo "##vso[task.setvariable variable=FOO]$FOO"
# Using the $() syntax during "compile time", the pipeline expands the variable
- bash: |
echo "$(FOO)"
# Using an environment variable in the script context at "runtime", bash expands the variable
- bash: |
echo "$FOO"Variables are expanded once when the pipeline run is started, and again, at the beginning of each step. Below you can see a simple example of this behavior.
jobs:
- job: build
variables:
- foo: bar
steps:
- bash: |
echo $(foo) # This will be bar
echo '##vso[task.setvariable variable=foo]baz'
echo $(foo) # This will also be bar, $(foo) expands before the step
- bash: echo $(foo) # This will be baz. The variable is expanded just before the stepVariable Syntax
As you’ve learned, you can set or read variables in two “environments” – the pipeline and script environments. While in each environment, how you reference variables are a little different. There are quite a few nuances you’ll need to watch out for.
Pipeline Variables
Pipeline variables are referenced in the YAML build definitions and can be referenced via three different syntax methods – macro, template expression and runtime expression.
Macro Syntax
The most common syntax you’ll find is macro syntax. Macro syntax references a value for a variable in the form of $(foo). The parentheses represent an expression that is evaluated at runtime.
When Azure Pipelines processes a variable defined as a macro expression, it will replace the expression with the contents of the variable. When defining variables with macro syntax, they follow the pattern <variable name>: $(<variable value>) eg. foo: $(bar).
If you attempt to reference a variable with macro syntax and a value does not exist, the variable will simply not exist. This behavior differs a bit between syntax types.
Template Expression Syntax
Another kind of variable syntax is called template expression. Defining pipeline variables this way takes the form of ${{ variables.foo }} : ${{ variables.bar }}. As you can see, it’s a bit more long form than macro syntax.
Template expression syntax has an added feature too. Using this syntax, you can also expand template parameters. If a variable defined with template expression syntax is referenced, the pipeline will return an empty string vs. a null value with macro syntax.
Template expression variables are processed at compile time and then overwritten (if defined) at runtime.
Runtime Expression Syntax
As the syntax type, suggested runtime expression variables are expanded only at runtime. These types of variables are represented via the format $[variables.foo]. Like template expression syntax variables, these types of variables will return an empty string if not replaced.
Like macro syntax, runtime expression syntax requires the variable name on the left side of the definition such as foo: $[variables.bar].
Script Variables
Working with variables inside of scripts is a bit different than pipeline variables. Defining and reference pipeline variables exposed in task scripts can be done one of two ways; with logging command syntax or environment variables.
Logging Commands
One way to define and reference pipeline variables in scripts is to use logging command syntax. This syntax is a bit convoluted but you’ll learn is necessary in certain situations. Variables are defined in this manner must be defined as a string in the script.
Setting a variable called foo with a value of bar using logging command syntax would look like below.
"##vso[task.setvariable variable=foo;]bar"I could not find a way to get the value of variables using logging commands. If this exists, let me know!
Environment Variables
When pipeline variables are turned into environment variables in scripts, the variable names are changed slightly. You’ll find that variable names become uppercase and periods turn into underscores. You’ll find many predefined or system variables have dots in them.
For example, if a pipeline variable called [foo.bar](<http://foo.bar>) was defined, you’d reference that variable via the script’s native environment variable reference method such as $env:FOO_BAR in PowerShell or $FOO_BAR in Bash.
We covered more of environment variables in the Script Environment section above.
Variable Scope
A pipeline has various stages, tasks and jobs running. Many areas have predefined variable scopes. A scope is namespace where when a variable is defined, its value can be referenced.
There are essentially three different variable scopes in a hierarchy. They are variables defined at:
- the root level making variables available to all jobs in the pipeline
- the stage level making variables available to a specific stage
- the job level making variables available to a specific job
Variables defined at the “lower” levels such as a job will override the same variable defined at the stage and root level, for example. Variables defined at the stage level will override variables defined at the “root” level but will be overridden by variables defined at the job level.
Below you can see an example YAML build definition which each scope being used.
variables:
global_variable: value # this is a global available to all stages and jobs
stages:
- stage: Build
variables:
stage_variable1: value3 # available in Build stage and all jobs
jobs:
- job: BuildJob
variables:
job_variable1: value1 # this is only available in BuildJob
steps:
- bash: echo $(stage_variable1) ## works
- bash: echo $(global_variable) ## works
- bash: echo $(job_variable1) ## worksVariable Precendence
Sometimes you’ll see a situation where a variable with the same name is set in various scopes. When this happens, that variable’s value will be overwritten according to a specific sequence giving precedence to the closest “action”.
Below you will see the order in which the variables will be overwritten starting with a variable set within a job. This will hold the greatest precedence.
- Variable set at the job level (set in the YAML file)
- Variable set at the stage level (set in the YAML file)
- Variable set at the pipeline level (global) (set in the YAML file)
- Variable set at queue time
- Pipeline variable set in Pipeline settings UI
For example, take a look at the YAML definition below. In this example, the same variable is set in many different areas but ultimately ends up with the value defined in the job. With each action, the variable’s value is overwritten the pipeline gets down to the job.
variables:
foo: 'global variable'
stages:
- stage: build
variables:
- name: foo
value: 'defined at stage level'
jobs:
- job: compile
variables:
- name: foo
value: 'defined at job level'
steps:
- bash: echo $(foo) # This will be 'defined at job level'Variable Types
You’ve learned about what variables are, what they look like, the contexts they can be executed in and more so far in this article. But what we haven’t covered is not all variables are alike. Some variables already exist when a pipeline starts and cannot be changed while others you can create, change and remove at will.
There are four general types of variables – predefined or system variables, user-defined variables, output variables and secret variables. Let’s get into covering each of these and understand each type of variable.
Predefined Variables
Within all builds and releases, you’ll find many different variables that exist by default. These variables are called predefined or system variables. Predefined variables are all read-only and, like other types of variables, represent simple strings and numbers.
An Azure pipeline consists of many components from the software agent executing the build, jobs being spun up when a deployment runs and other various information. To represent all of these areas, predefined or system variables are informally split into five distinct categories:
- Agent
- Build
- Pipeline
- Deployment job
- System
There are dozens of variables spread across each of these five categories. You’re not going to learn about all of them in this article. If you’d like a list of all predefined variables, take a look at the Microsoft documentation.
User-Defined Variables
When you create a variable in a YAML definition or via a script, you’re creating a user-defined variable. User-defined variables are simply all of the variables you, the user, define and use in a pipeline. You can use just about any name you’d like for these variables with a few exceptions.
You cannot define variables that start with the word endpoint, input, secret, or securefile. These labels are off-limits because they are reserved for system-usage and are case-insensitive.
Also, any variables you define must only consist of letters, numbers, dots or underscore characters. If you attempt to define a variable not following this format, your YAML build definition will not work.
Output Variables
A build definition contains one or more tasks. Sometimes a task sends a variable out to be made available to downstream steps and jobs within the same stage. These types of variables are called output variables.
Output variables are used to share information between components of the pipeline. For example, if one task queries a value from a database and subsequent tasks need the result returned, an output variable can be used. You then don’t have to query the database every time. Instead, you can simply reference the variable.
Note: Output variables are scoped to a specific stage. Do not expect an output variable to be made available in your “build” stage and also in your “testing” stage, for example.
Secret Variables
The final type of variable is the secret variable. Technically, this isn’t it’s own independent type because it can be a system or user-defined variable. But secret variables need to be in their own category because they are treated differently than other variables.
A secret variable is a standard variable that’s encrypted. Secret variables typically contain sensitive information like API keys, passwords, etc. These variables are encrypted at rest with a 2048-bit RSA key and are available on the agent for all tasks and scripts to use.
– Do NOT define secret variables inside of your YAML files
– Do NOT return secrets as output variables or logging information
Secret variables should be defined in the pipeline editor. This scopes secret variables at the global level thus making them available to tasks in the pipeline.
Secret values are masked in the logs but not completely. This is why it’s important not to include them in a YAML file. You should also know not to include any “structured” data as a secret. If, for example, { "foo": "bar" } is set as a secret, bar will not be masked from the logs.
Secrets are not automatically decrypted and mapped to environment variables. If you define a secret variable, don’t expect it to be available via
$env:FOOin a PowerShell script, for example.
Variable Groups
Finally, we come to variable groups. Variable groups, as you might expect, are “groups” of variables that can be referenced as one. The primary purpose of a variable group is to store values that you want to make available across multiple pipelines.
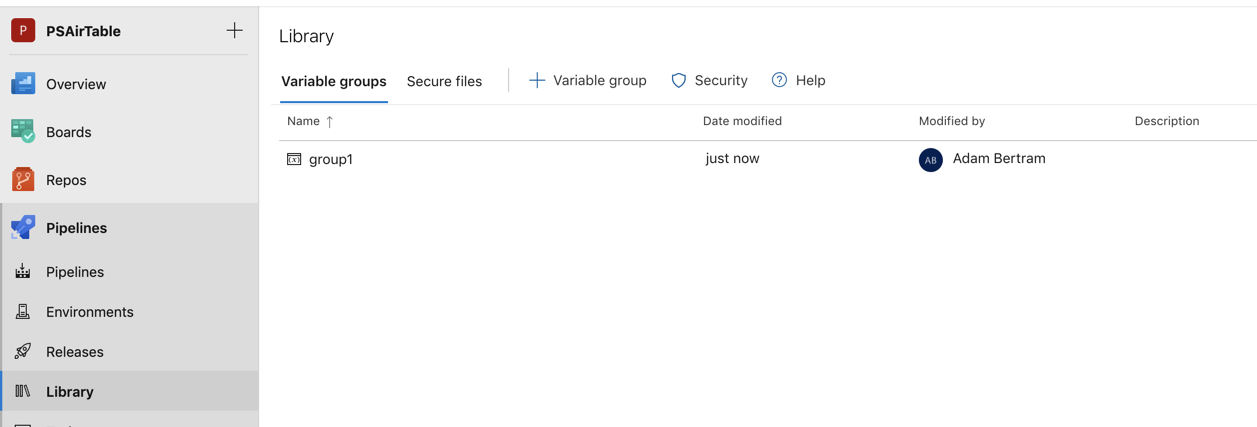
Unlike variables, variable groups are not defined in the YAML file. Instead, they are defined in the Library page under Pipelines in the UI.
Use a variable group to store values that you want to control and make available across multiple pipelines. You can also use variable groups to store secrets and other values that might need to be passed into a YAML pipeline. Variable groups are defined and managed in the Library page under Pipelines as shown below.
Once defined in the pipeline library, you can then make that variable group access in the YAML file using the syntax below.
variables:
- group: group1Variable groups are not, by default, available to all pipelines. This setting is made available when creating the group. Pipelines must be authorized to use a variable group.
Once a variable group is made access in the YAML file, you can then access the variables inside of the group exactly how you would any other variable. The name of the variable group isn’t used when referencing variables in the group.
For example, if you defined a variable group called group1 with a variable called foo inside, you would reference the foo variable like any other eg. $(foo).
Secret variables defined in a variable group cannot be accessed directly via scripts. Instead, they must be passed as arguments to the task.
Should a change be made to variable inside of a variable group, that change will automatically be made available to all pipelines allowed to use that group.
Summary
You should now have a firm knowledge of Azure Pipelines variables. You learned just about every concept there is when it comes to variables in this article! Now get out there, apply this knowledge to your Azure DevOps Pipelines and automate all the things!


